
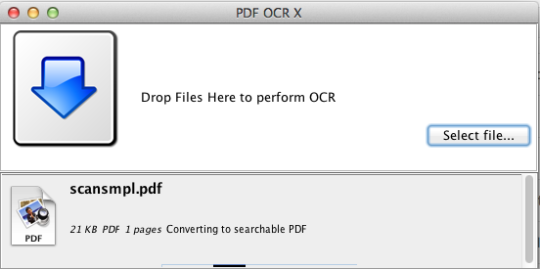
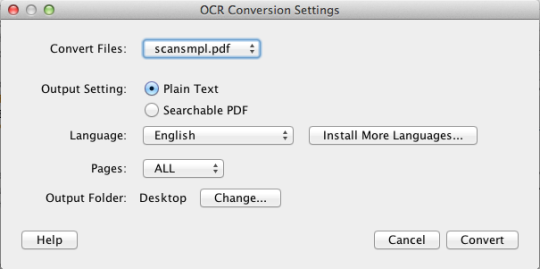
PDF OCR X - простая утилита перетаскивания для Mac OS X, которая преобразует ваши PDF-файлы и изображения в текстовые или поисковые PDF-документы. Он использует передовую технологию распознавания оптического распознавания (OCR) для извлечения текста PDF (или изображения), даже если этот текст содержится в изображении. Это особенно полезно для работы с PDF-файлами и изображениями, которые были созданы с помощью функции Scan-to-PDF в сканере или копире. Поддержка более 60 языков для OCR. Двигатель OCR основан на Tesseract. Community Edition поддерживает одностраничные PDF-файлы (или первую страницу многостраничных PDF-файлов). Для многостраничной поддержки PDF вам необходимо перейти на версию Enterprise Edition.
Что нового в этой версии:
Версия 2.1.1 добавляет поддержку Mojave , и улучшает пользовательский интерфейс на дисплеях сетчатки.
Что нового в версии 2.0.8:
Исправлена проблема с обработкой некоторых PDF-файлов с вращением.
Ограничения :
Community Edition ограничивается одностраничными PDF-файлами и изображениями.


Комментарии не найдены