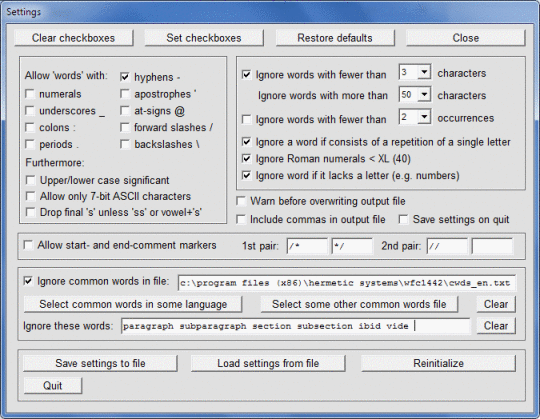
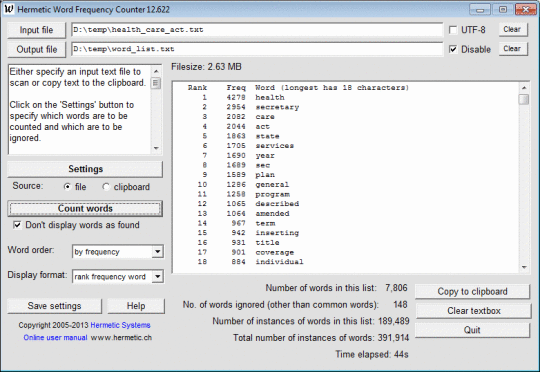
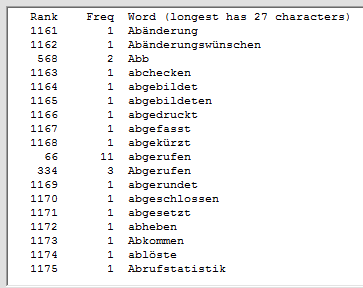
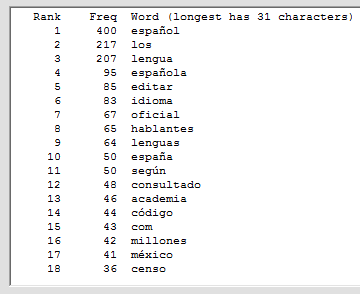
Это программное обеспечение сканирует файл docx MS Word или текстовый файл (включая HTML и XML-файлы) с текстом, закодированным через ANSI или UTF-8, и подсчитывает частоты разных слов. Слова, которые найдены и отображаются, можно заказать по алфавиту или по частоте. Символы, которые могут отображаться в словах, могут быть указаны, поэтому программе может быть предложено разрешить или запретить слова с цифрами, дефисами, апострофами, подчеркиваниями или двоеточиями, чтобы игнорировать слова, которые являются короткими или которые происходят нечасто, для обработки верхнего / нижнего регистра как значимые или нет, и игнорировать слова (например, общие слова, такие как «это»), содержащиеся в указанном файле. Это программное обеспечение может использоваться с текстом на других языках, кроме английского, в частности, с текстом на французском, немецком, итальянском и испанском языках. Язык текста обнаруживается автоматически, и соответствующий файл «общих слов» (со словами, которые нужно игнорировать) необязательно загружается. Результаты могут быть записаны в выходной файл и затем могут быть прочитаны в Excel для дальнейшей обработки.
Что нового в этой версии:
Версия 19.36: возможность конвертировать множественное число слова к единственному для подсчета.
Что нового в версии 19.26:
Улучшена установка.
Что нового в версии 18.22:
Улучшена обработка XML-файлов.
Что нового в версии 16.52:
Версия 16.52 может включать неопределенные обновления, улучшения или исправления ошибок.
Что нового в версии 16.42:
Версия 16.42 может включать неопределенные обновления, улучшения или исправления ошибок.
Что нового в версии 16.22:
Версия 16.22 может включать неопределенные обновления, улучшения или исправления ошибок.
Что нового в версии 15.52:
Версия 15.52 исправлена ошибка в распознавании текстовых файлов с кодировкой UTF-8.
Что нового в версии 14.42:
Добавлена поддержка файлов со смешанным текстом на английском / китайском языке.
Ограничения
30-дневная пробная версия, ограниченная функциональность

Комментарии не найдены