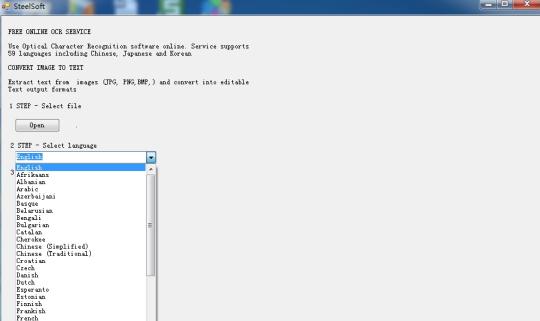
распознавания текста с изображений с помощью Двигатель Тессеракт OCR, основанный на технологии облачных в.
Используйте оптическое распознавание символов программное обеспечение онлайн. Услуги поддерживает 59 языков, включая китайский, японский и корейский. Извлечение текста из изображений (JPG, PNG, BMP, TIF) и конвертировать в редактируемые форматы вывода текста.
Он основан на облачных технологий, и очень известного OCR Engine (Тессеракт OCR Engine), так что есть только сотни КБ, но он может извлечь текст в 59 языках, от образов.
Он поддерживает несколько языков: болгарский, каталонский, чешский, датский, голландский, английский, финский, французский, немецкий, греческий, венгерский, индонезийский, итальянский, латышский, литовский, норвежский, польский, португальский, румынский, русский, сербский, словацкий, словенский , испанский, шведский, тагальский, турецкий, украинский, вьетнамский и т.д.
Что нового В этом выпуске:..
Версия 5.0 включает усовершенствования UE

Комментарии не найдены