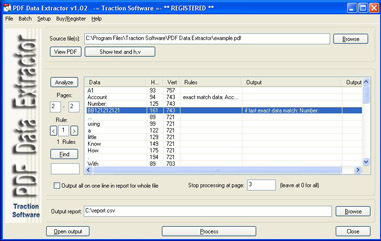
PDF Data Extractor может извлекать определенную текстовую информацию в PDF-формате. Это идеальный продукт, если у вас есть, к примеру, заявление в формате PDF, в котором вам необходимо извлечь данные, такие как номер счета, имя, адрес и вывести эту информацию в файл Excel CSV. Он использует горизонтальное, вертикальное соответствие текстового положения и для более расширенного соответствия имеет систему правил для условного сопоставления, например. Учитывайте только, когда номер счета: текст находится на той же странице. Различные поля можно также объединить в одно, так что имя и фамилия могут выводиться как одно поле в CSV-файле, преобразовывать формат электронных таблиц pdf в файлы csv, доступно много вариантов: извлечение данных, запуск в командной строке, вывод заголовка , Поле номера страницы, поле имени файла, пакетный список файлов для обработки.
Также теперь можно переименовывать или копировать файлы в новое место на основе извлеченных данных.
ПРИМЕЧАНИЕ. Это программное обеспечение является автономным, то есть не требует запуска Adobe Acrobat
Оценочные ограничения: - скриншоты, пробный текст и 5 файлов в пакетном режиме.
Вам нужен специальный экстрактор данных, созданный для ваших конкретных PDF-файлов?
Мы сделали различные варианты этого продукта для более сложных отчетов, таких как полицейские отчеты, счета-фактуры и т. Д. Для вывода csv-файлов, с более простым интерфейсом в / из файла - свяжитесь с нами для получения разумной цитаты.
Что Является новым в этом выпуске:
- Версия 1.05:
Что нового в версии 1.04:
Версия 1.04:
1. добавлена корректировка строки для плавающих размеров строк, сопоставление с текстом h.
2. измененный текстовый дамп для включения всех шрифтов, встроенных и подмножеств шрифтов.
Ограничения :
Nags, пробная версия с 5 файлами, пробный текст
Комментарии не найдены