Свободное программное обеспечение распознавания для извлечения текста из файлов изображений и PDF-элементов. Графический интерфейс пользователя (GUI) для двигателя Тессеракт OCR.
Приложение проста в установке и, что более важно, свободно использовать, с открытым исходным кодом и 100% рекламного и шпионского ПО бесплатно.
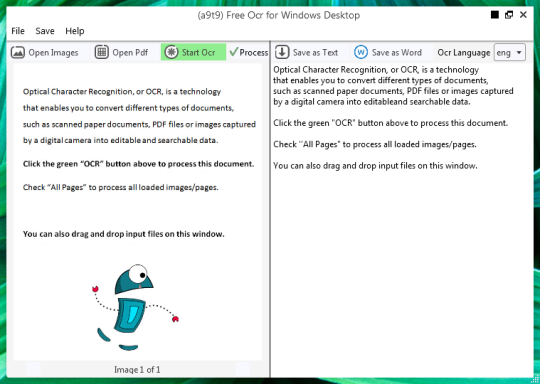
Вы можете открыть файл изображения или PDF. Содержание исходного файла будет отображаться в левом окне. Если ваш документ, как более одной страницы, или если вы открыли многостраничные документы, используйте стрелки внизу, чтобы переключаться между ними,
Вы начинаете OCR нажав зеленую кнопку OCR, и вы увидите результат на второй правом окне. Вывод текста может быть сохранен в виде текстового файла или документа Word.
К сожалению, качество преобразования не так уж велика. За сценой он использует открытым исходным кодом OCR Engine TESSERACT. Качество варьируется от языка к языку. - Так что идти вперед и испытания, если это достаточно для ваших нужд
Для разработчиков программного обеспечения и вундеркиндов: бесплатная OCR для инструмента рабочего стола Windows, по существу, графический пользовательский интерфейс передний конец (GUI) для двигателя Тессеракт OCR. Полный исходный код доступен (лицензия GPL).
Двигатель OCR программного обеспечения поддерживает следующие язык OCR: английский, французский, итальянский, немецкий, испанский, бразильский португальский и голландский. Начиная с версии 3 можно признать арабский, болгарский, каталанский, китайский (упрощенный и традиционный), хорватский, чешский, датский, голландский, английский, немецкий (стандартный и фрактура скрипт), греческий, финский, французский, иврит, хинди, венгерский, индонезийский, итальянский, японский, корейский, латышский, литовский, норвежский, польский, португальский, румынский, русский, сербский, словацкий (стандартный и фрактура скрипт), словенский, испанский, шведский, тагальский, тамильский, тайский, турецкий, украинский и вьетнамский.
Комментарии не найдены