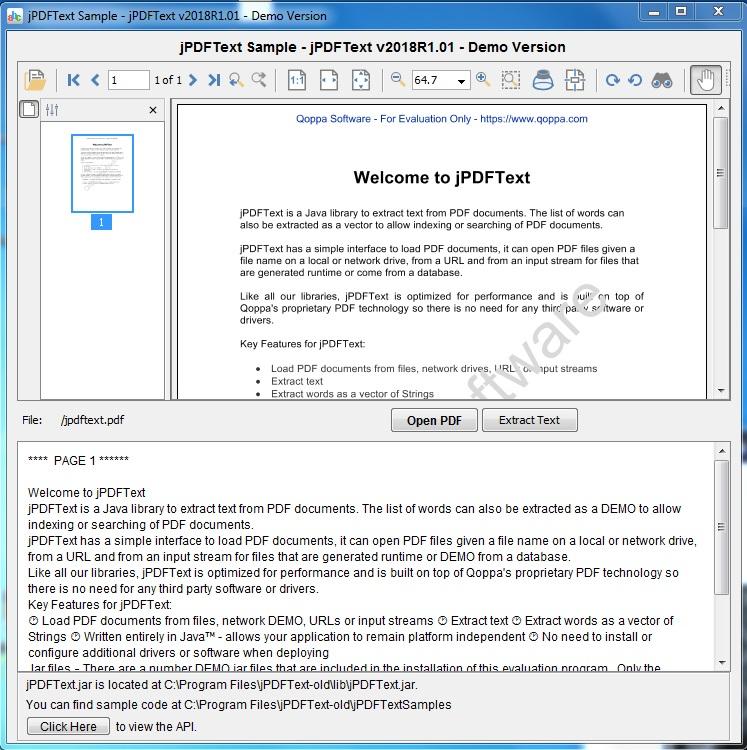
jPDFText - это библиотека Java для извлечения текста из документов PDF. С помощью jPDFText документы PDF можно обрабатывать для извлечения текстового содержимого для архивирования, хранения, поиска или индексирования. jPDFText построен поверх проприетарной технологии PDF Qoppas, поэтому вам не нужно устанавливать стороннее программное обеспечение или драйверы. Поскольку он написан на Java, он позволяет вашему приложению оставаться независимым от платформы и работать в Windows, Linux, Unix (Solaris, HP UX, IBM AIX), Mac OS X и любой другой платформе, поддерживающей среду выполнения Java.
Основные характеристики:
Загрузите документы PDF из файлов, сетевых дисков, URL-адресов или потоков ввода.
Извлечь текст в логическом порядке чтения.
Извлечь слова как вектор строк.
Работает на Windows, Linux, Unix и Mac OS X (100% Java).
Нет необходимости устанавливать или настраивать дополнительные драйверы или программное обеспечение при развертывании.
Протестировано на JDK 1.4.2 и выше.
Комментарии не найдены